Text Conversions
All text conversion tools in the TEv2 toolbox convert particular tools consists of the various ways in which texts can be converted.
Examples of text conversions
One example is the conversion of so-called TermRefs into renderable refs, i.e., the conversion of texts such as this: [TermRefs](@), i.e., the 'raw' texts that authors write, into "TermRefs", i.e., a nicely rendered version of that raw text, that has additional properties, in this case that it is emphasized, and if you hover your mouse over it, you'll get a popup with the definition of the term.
Another example is the conversion of a so-called MRGRef into (the body/contents of) a [human readable glossary]. The MRGRef points to a particular (version) of a terminology, and the text conversion process sees to converting it to (the body/contents of) a HRG. This is how the TEv2 glossary was generated.
Text conversions must work in different contexts. For example the context where (static) websites are generated from the raw, authored texts requires different conversions than when the same raw texts are to be rendered into a PDF, or LaTeX document. Also, it may be necessary to provide authors with different syntax options to mark text fragments for conversion.
Text Conversion Tools
The text conversion tools in the TEv2 toolbox, such as the TRRT and HRGT, operate in a context as described in the below figure:
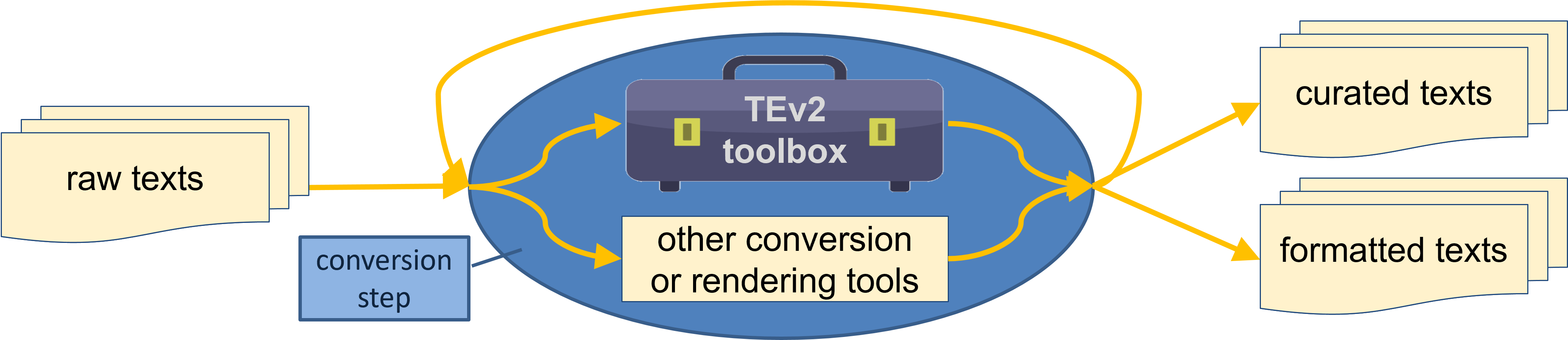 Figure 1: Repeated conversions turn raw texts into formatted texts and/or curated texts
Figure 1: Repeated conversions turn raw texts into formatted texts and/or curated texts
Each such tool can be called to perform a text conversion step, i.e. a process in which a specified set of (input, or source) files are converted into another set of (output, or target) files. While each text conversion tool has its particular way of working, they are all designed to follow a specific sequence of steps. This enables users to configure (customize) how the tool works whenever it is called.
Thus, the TRRT, whose task is to convert term refs into renderable refs, can be configured to use your own, customized term ref syntax. It can also be configured to produce your own particular flavor of renderable refs, by specifying custom converters.
Text Conversion Steps
All text conversion tools convert (input) text files into results (output text files) by locating particular text patterns, doing some processing, and constructing texts that are used to replace the located text patterns with. This is illustrated in the figure below:
 Figure 2: The generic parts of a Text Conversion Step
Figure 2: The generic parts of a Text Conversion Step
A text conversion step works on a single source (file)1, as follows:
The first part consists of finding the locations of specific text patterns as specified by the interpreter that is configured for use. The interpreter is expected to populate the named capturing groups that are defined in the interpreter profile of the TEv2 tool in which it is used. This interpreter profile is defined in the specifications of each TEv2 tool that uses it.
The second part is a processing step, in which the tool collects (the values of) the named capturing groups as well as other resources, and creates a set of moustache variables as defined for the converter profile of that tool. The kinds of resources that are used and the converter profile are particular to each tool, and are defined in the specifications for that tool.
The third part consists of replacing the found text patterns with (one or more2) texts that the tool gets from invoking the converter that is configured for use. The converter is designed in such a way that it uses the values of the moustache variables in the converter profile to construct a text with.
What is specific for a Text Conversion Tool
Every TEv2 text conversion tool has one particular
- interpreter profile, i.e., a specification of the named capturing groups that an interpreter should populate if it is to be useable for that tool. The tool-specific interpreter profile is specified in the documentation of that tool.
- converter profile, i.e., a specification of the moustache variables that a converter can use for the construction of the replacement text. The tool-specific converter profile is specified in the documentation of that tool.
Configuration of a Text Conversion Tool
Every time a TEv2 text conversion tool is executed, it will use a particular
- interpreter, that it will use to find the text patterns that need to be replaced, and to populate the named capturing groups as defined in the interpreter profile of that tool.
- converter, that it will use to construct the replacement texts for the text patterns located by the interpreter. The converter may use the moustache variables as defined in the converter profile of that tool.
A tool can be instructed to use a particular interpreter and/or converter by:
- not specifying it, in which case the defaults are used that are specified for that tool;
- specifying it in a configuration file that is used when calling the tool. This overrides any defaults that the tool may have;
- specifying as a command-line argument that is used when calling the tool. This overrides any specifications in the configuration file if that were also used.
Particular text conversion tools may have the option of specifying the converter to be used as part of the text pattern that is located by the interpreter of the tool. An example of this is the HRGT.
Specifying converters as part of the text pattern that is located by the interpreter of the tool is expected to result in 'messy texts'; it's the cost authors pay for using such flexibility (insofar that is (going to be) implemented). The 'price' should then be that when that is specified, it should take precedence over anything else.
Perhaps we need some text that documents that once a tool has decided what the sourcer of a particular (array of) arguments is, it should stick to that. In other words, if the commandline specifies a single converter and the config file specifies multiple ones, then the source is the commandline, and con[2] that is specified in the config file does not get used.
Also the con[error] is NOT one of the elements of the con array for this matter, but is/should be an argument/parameter in its own right, so that - using the example of the previous paragraph - if the commandline doesn't specify a con[error] while the config file does, then the con[error] as specified in the config file is used where necessary.
- If a tool is instructed to work on multiple files, they will be processed sequentially.↩
- the TRRT replaces every occurrence of a text that its interpreter finds - i.e., a TermRef - with one text that is constructed by its converter - a renderable ref. The HRGT, however, replaces every occurrence of a text that its interpreter finds - i.e., an MRGRef with a sequences of texts, each of which is constructed by its converter - a HRG entry.↩