TEv2 - Architecture
TEv2 is designed to support an ever increasing variety of raw text formats, and its toolbox will - over time - be filled with an increasing number of tools that will support an increasing number of 3rd party rendering tools. This section shows the architecture that allows this to become reality.
The architecture is not yet fully aligned with the (momentarily developing) ideas as explained in the section Text Conversion Steps. This is still work that needs to be done.
This architecture is based on the ToIP/eSSIF-Lab Terminology Model, which assumes that every author/group constitutes a so-called terms-community that curates one (or more) scope(s), that contains e.g. definitions, terms, tags etc. that constitute the author/group's terminology. An overview is given in the figure below:
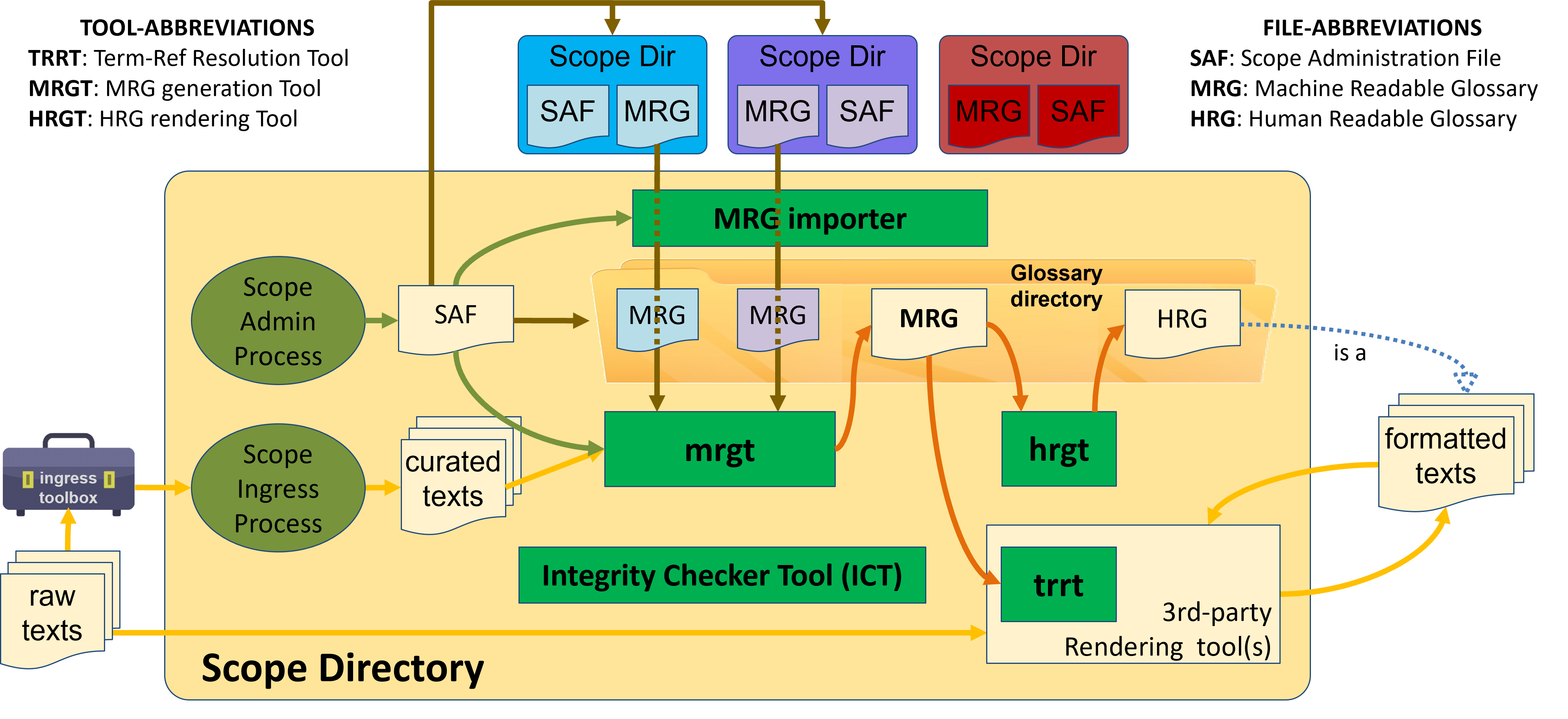
The figure shows a yellow rounded rectangle, called the scope directory. All files - documents and other stuff - that belongs to the scope is in this directory. It contains, e.g., the Scope Administration File (SAF), and the glossary directory (that contains, e.g., machine readable glossaries (MRGs) that either are imported from other scopes, or generated from within the scope itself, and human-readable glossaries (HRGs) that are generated from within the scope itself.)
The green rectangles represent tools from the TEv2 toolbox as they would run within a particular scope. You can see, for example, that the mrgt depends on the SAF, on curated texts and possibly also MRGs that have been imported from other scopes, and generates an MRG.
Outside of the scope we find other scopedirs (that have their own SAFs, MRGs, etc.). From some of them, their MRGs can be imported - that's what the MRG importer tool does (as specified by the SAF of the scope within which it operates).
Also, outside of the scope we find raw texts, that can either be processed by the Scope Ingress Process so as to become curated texts, which are files that may contain, e.g., definitions, conceptual models, etc. Alternatively, raw texts can be processed by 3rd party rendering tools to become so-called 'formatted texts', such as pages in a static website (such as this page), PDF files, or other. The 3rd party rendering tools can use the TermRef Resolution Tool (TRRT) to convert references in the raw texts that have particular formats/syntaxes into artifacts that are rendered in a very specific way to help readers understand particular terms, an example of which are the popups that you can see on this website when you hover over a term that contain their definitions.
The following sections explain the parts in a bit more detail.
Raw Texts
Raw texts are generally simple texts, e.g., in a wiki-format or markdown. The idea is that they can be easily written and modified by non-technical people. Raw texts are the basis of all texts - papers, documentation, etc. that are to be used within a particular scope.
Raw texts serve roughly either of the following purposes:
- they are the source for a document that has content that is relevant to the scope. For example, if the purpose of the scope is to create and maintain a software application, such documents might contain the requirements, specifications, installation procedures, manuals etc. for that software application. Raw texts that fall in this category are typically processed by third party rendering tools to produce something that is readable by the intended audience. Such texts may contain so-called TermRefs, which makes for better reading by the audience.
- they specify the concept (better: semantic unit) behind a paricular term. For example the term definition can be explained in a file that specifies the criterion for distinguishing between what is, and what is not, a definition within the context of the scope; it can also describe what the problems are with them, ways to create them and use them, etc. Raw texts that fall in this category are geared towards becoming so-called curated texts.
TRRT
The TermRef Resolution Tool (TRRT) is a tool that can be run from the command-line, and also be used e.g., by Github actions, to convert files that might contain TermRefs into files in which these TermRefs are converted into so-called renderable refs, which could, e.g., be a hyperlink with a popup frame that contains the definition of the term being referenced. The tool allows for customizing the structure to which a TermRef is being converted, which makes it useful in many contexts.
Curated Texts
To the left of the figure, you can see that some raw texts are 'ingressed' into the scope directory, and thereby have become so-called curated texts (a specification of which is provided in the Curated Texts description). These texts typically contain descriptions of terms, definitions, examples, etc., that help interested parties to formulate and understand the concepts that they need.
Scope Ingress Process
Curated texts are the result of subjecting raw texts to one or more [text conversions](#steps). This is the Scope Ingress Process. It is run by the curators of the scope. The curators define the kinds of raw texts that can be ingressed, and they make sure the [ingress tools](#ingress-tools) exist that can interpret such texts, and that the result of their interpretation is fed into the converter-tool that produces curated texts. Curators should communicate with contributors and authors concerning the kinds of raw texts that can be ingressed.Ingress Tools
The set of ingress tools consists of the set of interpreters and converters (see the section on text conversions) that enable a variety of easily editable files, such as Terms Wiki pages to be converted into curated texts.
SAF
The curators of a scope create and maintain the scope's administration file (SAF), which is called saf.yaml and is located in (the root of) the scope directory. This file contains meta-data concerning the scope itself, the locations of its directories (and glossary files), the locations of the scope directories of (selected) other scopes, and a specification of the terms (MRG entries) that are part of the various versions of its terminology that are actively maintained. Further details are in the SAF specs.
MRG
The curators also organize when and how the scope's Machine Readable Glossaries (MRGs) are created. An MRG is not a real glossary, but rather a (machine readable) inventory of all terms that are part of (a specific version of) the scope's terminology, and related (meta)data. TEv2 hails the principle that tools that need to learn about terms, the semantic units that these terms represent, and the curated texts that document them, from a particular scope, should only need to inspect the (appropriate) MRG of that scope to find what they need. Further details are in the MRG specs.
Glossary Directory
The Glossary Directory or glossarydir is a directory within the scopedir where all MRGs are located. One should expect to find an MRG for every terminology that is maintained within the scope itself, as well as any MRGs that have been imported by the MRG importer tool. Also, one would expect to find every HRG that has been generated in this scope. In future, this would also be the location where machine- or human readable dictionaries could be found.
MRG Import Tool
The MRG importer tool serves to get any MRG that may be needed within a particular scope, and make it available in the scope's glossarydir. The idea behind this is that various tools that may need such MRGs would not need to include such code.1
MRGT
The MRG is created by the MRGT tool. This tool takes the scope's curated texts as input, as well as MRGs from other scopes (which it expects to be available in the glossarydir from which it can 'import' terms when needed. The SAF of the scope tells the MRGT which terms are to go into the MRGs that are to be generated.
HRG
The Human Readable Glossary or HRG is a (real) glossary that humans are expected to read/use. It is a formatted text, which means that it might appear in one of a plethora of formats. Within a scope, we assume a specific format is chosen that is appropriate for its users, and that will serve as the default HRG for that scope. The HRG is not a formatted/rendered version of the entire MRG: it typically only lists the terms that are assocated with specific kinds of semantic units, specifically the type concept.
HRGT
We will use the term HRGT to generically refer to any tool that either produces a HRG directly, or that produces inputs for other, third party rendering tools that will then generate the HRG. Typically, a HRGT will extract a subset of the terms (better: MRG entries) from the MRG, sort them, resolve TermRefs where appropriate, and do whatever else is necessary to generate (the files that third party tools pick up to) generate the HRG. We expect to see various flavours of this tool, or a single tool that can create HRGs in different formats, allowing curators to get the kind of HRG that is the most appropriate for their purposes.
Rendering tool plugins/addons
We envisage that existing 3rd party rendering tools may benefit from extensions (plugins, add-ons) that provide features that help readers to better understand rendered texts. One example is the Docusaurus Terminology plugin of GRNET that was used in TEv1 (the predecessor of TEv2), which enables the 'sticking out' of terms in the rendered text, providing a popup with a short explanation of the term, and providing a link to the page that documents the concept. While the development of such plugins is outside the scope of TEv2, using them (e.g. by the HRGT) may be within scope.
Integrity Checker Tool (ICT)
People that develop these tools, as well as people that contribute to the curation of curated texts, the SAF, etc., are only human, and sooner or later make a mistake that is hard to find and correct without any help. To facilitate the detection, identification and recovery from such mistakes, there is an Integrity Checker Tool (or ICT). This ICT tests the integrity of (a selection of) the data in files that are curated within a particular scope, i.e. the SAF, the MRGs, and curated texts. The integrity checking of other data, e.g. formatted texts, such as HRGs, is outside the scope of the ICT. Further details are in the ICT specs.